

django微信开发的心路历程
(非微信官方)微信开发python sdk
http://wechat-python-sdk.com/
微信开发者文档
http://mp.weixin.qq.com/wiki/10/6380dc743053a91c544ffd2b7c959166.html
第一步:填写服务器配置
第二步:验证服务器地址的有效性
加密/校验流程如下:
- 将token、timestamp、nonce三个参数进行字典序排序
- 将三个参数字符串拼接成一个字符串进行sha1加密
-
开发者获得加密后的字符串可与signature对比,标识该请求来源于微信
signature = request.GET.get("signature", None) timestamp = request.GET.get("timestamp", None) nonce = request.GET.get("nonce", None) echostr = request.GET.get("echostr", None) tmp_list = [Token, timestamp, nonce] tmp_list.sort() tmp_str = "%s%s%s" % tuple(tmp_list) tmp_str = hashlib.sha1(tmp_str).hexdigest() if tmp_str == signature: return HttpResponse(echostr)
如何接受用户的信息
信息就像一个表单一样发送微信服务器,再通过微信服务器发给我的服务器 xml
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[this is a test]]></Content>
<MsgId>1234567890123456</MsgId>
</xml>
解析xml
首先想到使用django rest framework 方便的使用一个request.data接受任意格式的数据,以字典的形式方便地提取值
http://www.django-rest-framework.org/api-guide/renderers/
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES': (
'rest_framework_xml.parsers.XMLParser',
),
'DEFAULT_RENDERER_CLASSES': (
'rest_framework_xml.renderers.XMLRenderer',
),
}
上述解析方法只是一种,还可以使用lxml库,Beautifulsoup等库进行解析
使用firefox模拟发包工具HttpRequester模拟发包进行测试,成功 部署到服务器上,失败,一直提示“该公众号暂时无法提供服务,请稍后再试” 查看微信文档
一旦遇到以下情况,微信都会在公众号会话中,向用户下发系统提示“”:
- 开发者在5秒内未回复任何内容
- 开发者回复了异常数据
检查数据,并没有异常回复
用户的信息是先经过微信服务器的
使用微信的调试工具调试
调试工具只是提示了“请求错误”,完全没有实质性的提示
检查服务器报错,发现通过微信调试,报错415
HTTP 415 错误 – 不 支持的媒体类型(Unsupported media type)
而自己通过模拟器发送是 200成功的
发现自己的模拟器发送形式是
'CONTENT_TYPE': 'application/xml'
检查下通过微信调试器受到的内容的http头部相关信息
print request.META
发现一行
'CONTENT_TYPE': 'text/xml'
跟我的模拟器不一样,问题应该出现在这
google了一下这2者的差别
查看 rest_framework.xml的相关源码,
lib/python2.7/site-packages/rest_framework_xml/parsers.py
media_type = 'application/xml'
只能正确解析这种格式
只好修改源码,以能解析'text/xml'
再次测试,成功!
原本想要以django resframework 默认的xml回复形式,没有成功,必须严格按照微信官方定义的格式
网页授权获取用户基本信息
如果用户在微信客户端中访问第三方网页,公众号可以通过微信网页授权机制,来获取用户基本信息,进而实现业务逻辑。
在确保微信公众账号拥有授权作用域(scope参数)的权限的前提下(服务号获得高级接口后,默认拥有scope参数中的snsapi_base和snsapi_userinfo)
普通用户申请的个人账号没有这样的权限,需要升级至服务号,需要一些组织信息,一定的金额。可以通过以下网站申请测试账号,获取所有权限,用以开发调试。
http://mp.weixin.qq.com/debug/cgi-bin/sandbox?t=sandbox/login
这里忽略了一个细节,困扰了我很久
在微信公众号请求用户网页授权之前,开发者需要先到公众平台官网中的开发者中心页配置授权回调域名
- 因此请勿加 http:// 等协议头
- 可以填写域名或者ip地址
第一步:用户同意授权,获取code
这里需要引导微信用户开打一个网页,所以要自己设计引导页。例如:
用户点击同意授权后,重定向到 https://open.weixin.qq.com/connect/oauth2/authorize?appid=你的appid&redirect_uri=授权后重定向的回调链接地址,请使用urlencode对链接进行处理&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect
使用到 Python urllib库进行urlencode
data = urllib.urlencode({
'appid': appID,
'redirect_uri': 'http://121.42.154.163/authorization/code' # 这是我的网站, 授权后重定向的回调链接地址
'response_type': 'code', # 返回类型,请填写code
'scope': 'snsapi_userinfo',
# 应用授权作用域,snsapi_base (不弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo (弹出授权页面,可通过openid拿到昵称、性别、所在地。并且,即使在未关注的情况下,只要用户授权,也能获取其信息)
'state': 'STATE', # 重定向后会带上state参数,开发者可以填写a-zA-Z0-9的参数值,最多128字节
})
这时候,页面将跳转至 redirect_uri/?code=CODE&state=STATE 即向服务器GET请求
这里有个小问题困扰了我很久: redirect_uri/? redirect_uri后的斜杠没加,http 进行301跳转,多出了nsukey参数,这个参数好像与分享有关,所以一直请求失败。
第二步:通过code换取网页授权access_token
通过上一步 服务器受到了 GET redirect_uri/?code=CODE&state=STATE 请求,也就是说能通过
request.GET.get(‘code’)获得用户的传来的code值
拿到这个值后,换取网页授权access_token
获取code后,请求以下链接获取access_token: https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
正确返回时,受到微信服务器的json数据
{
"access_token":"ACCESS_TOKEN",
"expires_in":7200,
"refresh_token":"REFRESH_TOKEN",
"openid":"OPENID",
"scope":"SCOPE"
}
使用Python的json库解析json,获得数据字典
response_dic = json.loads(response.read()) # 解析json
第三步:刷新access_token(如果需要)
先往下看是否需要
第四步:拉取用户信息(需scope为 snsapi_userinfo)
通过第三步 如果网页授权作用域为snsapi_userinfo,则可以通过access_token和openid拉取用户信息了。
GET https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN
正确时返回的JSON数据包如下:
{
"openid":" OPENID",
" nickname": NICKNAME,
"sex":"1",
"province":"PROVINCE"
"city":"CITY",
"country":"COUNTRY",
"headimgurl": "http://wx.qlogo.cn/mmopen/g3MonUZtNHkdmzicIlibx6iaFqAc56vxLSUfpb6n5WKSYVY0ChQKkiaJSgQ1dZuTOgvLLrhJbERQQ4eMsv84eavHiaiceqxibJxCfHe/46",
"privilege":[
"PRIVILEGE1"
"PRIVILEGE2"
],
"unionid": "o6_bmasdasdsad6_2sgVt7hMZOPfL"
}
第五步:信息展示
通过上一步,抽取其中的个人信息nickname, sex, province, city, country, headimgurl作为信息展示 用django的模板渲染返回给用户
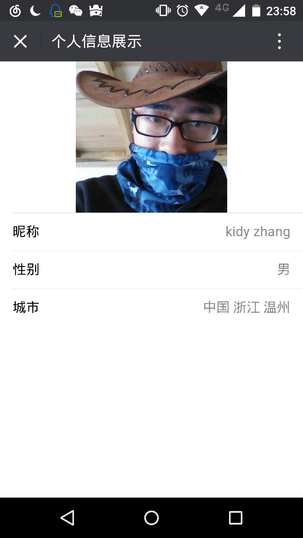
参考: http://mp.weixin.qq.com/wiki/2/ae9782fb42e47ad79eb7b361c2149d16.html 使用微信官方提供的ui框架, 设计了部分前端页面
就这样,网页授权的功能已经实现了
调整代码,提高可维护性,适应生产环境
- 配置Debug
- 配置logger
- 配置STATICFILES_DIRS, TEMPLATES
- 此处没有涉及数据保存,生产环境下要配置好MySql,Redis等
- 使用reverse,而不是填写具体url, 使用 {% load staticfiles %}等,提高可维护性
- 这里我用’redirect_uri’: request.get_host() + reverse(‘get_code’) 提高可维护性 测试的时候一直跳转不成功,困扰许久,发现request.get_host()只返回ip地址,没有http/https字段 改正为’redirect_uri’: ‘http://’ + request.get_host() + reverse(‘get_code’)